HTTP - Hypertext Transfer Protocol
HTTP ist das Kommunikationsprotokoll im World Wide Web (WWW). Die Kommunikation erfolgt zwischen einem Client und einem Server. Der Client fordert Ressourcen, meist Dateien, von einem Server an und schickt diese dem Client zu. Der Client, in der Regel ein Webbrowser übernimmt dann die Darstellung von Texten und Bildern und kümmert sich um das Abspielen von Audio- und Video-Daten.
Ursprünglich war HTTP dazu gedacht statische Inhalte von jeweils einem Server abzurufen. Inzwischen finden heute wesentlich mehr Interaktionen zwischen einem Webbrowser und auch mehreren Servern statt. Gleichzeitig nimmt die Anzahl der Anwendungen und Dienste zu, die HTTP als Kommunikationsprotokoll nutzen. Probleme haben insbesondere Webanwendungen, die auf eine möglichst geringe Latenz angewiesen sind und mehrere gleichzeitige Verbindungen zu unterschiedlichen Servern benötigen.
- Webapplikationen, die dynamische Inhalte nachladen.
- Videokonferenz-Systeme mit Web-Clients
- Namensauflösung per DNS over HTTP
- Push-Dienste
Damit hat sich die Nutzung von HTTP als Kommunikationsprotokoll weit davon entfernt, was sich Tim Berners-Lee mit dem World Wide Web ursprünglich gedacht hatte.
HTTP im OSI-Schichtenmodell
| Schicht | Dienste / Protokolle / Anwendungen | |||
|---|---|---|---|---|
| Anwendung | HTTP | IMAP | DNS | SNMP |
| Transport | TCP | UDP | ||
| Internet | IP (IPv4 / IPv6) | |||
| Netzzugang | Ethernet, ... | |||
Wie funktioniert HTTP?
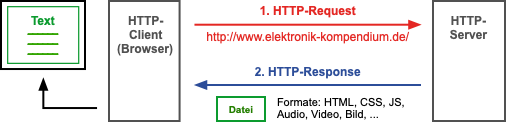
Die Kommunikation findet nach dem Client-Server-Prinzip statt. Der HTTP-Client (Browser) sendet seine Anfrage (HTTP-Request) an den HTTP-Server (Webserver/Web-Server). Dieser bearbeitet die Anfrage und schickt seine Antwort (HTTP-Response) zurück. Nach der Antwort durch den Server ist diese Verbindung beendet. Typischerweise finden gleichzeitig mehrere HTTP-Verbindungen statt.
Die Kommunikation zwischen Client und Server findet auf Basis von Meldungen im Text-Format statt. Die Meldungen werden standardmäßig über TCP auf dem Port 80 (Richtung Server) abgewickelt. Die Meldungen werden Request und Response genannt und bestehen aus einem Header und den Daten. Der Header enthält Steuerinformationen. Die Daten entsprechen einer Datei, die der Server an den Client schickt oder im umgekehrten Fall Nutzereingaben, die der Client zur Verarbeitung an den Server übermittelt. Dateien kann der Server aber nur mit Hilfe eines zusätzlichen Programms oder Skriptes entgegennehmen.
HTTP-Versionen im Vergleich
- HTTP/1.1 muss alle HTTP-Requests (z. B. HTML, CSS oder JavaScript) sequenziell abarbeiten (Pipelining). Das bedeutet, dass pro Request eine TCP-Verbindung und bei HTTPS zusätzlich ein TLS-Handshake erzeugt wird. Der dabei entstehende Overhead ist enorm.
- HTTP/2 kann mit der Funktion Stream Multiplexing mehrere Requests und Responses parallel in einer einzige TCP-Verbindung übertragen. Mehrere HTTP-Requests zum gleichen Webserver erzeugen also nicht die gleiche Anzahl an TCP-Verbindungen, sondern nur eine.
- HTTP/3 nutzt anders als die vorherigen HTTP-Versionen nicht mehr TCP, sondern das auf UDP basierende QUIC (Quick UDP Internet Connections). QUIC beinhaltet auch den TLS-1.3-Handshake und beschleunigt den Verbindungsaufbau.
HTTP/1.1
Ursprünglich wollte Tim Berners-Lee mit dem World Wide Web statische Inhalte per Links miteinander verknüpfen. Per HTTP sollten einzelne Ressourcen mit einem Client von einem Server abgerufen werden. Inzwischen finden heute wesentlich mehr Interaktionen zwischen Webbrowser und Server statt.
HTTPS - HTTP Secure
HTTPS ist eine Kombination aus HTTP und TLS, um die Verbindung zwischen Client und Server zu authentifizieren und zu verschlüsseln.
HTTP/2
Die wesentlichen Bestandteile von HTTP bleiben bei HTTP/2 gleich. Zum Beispiel das Client-Server-Prinzip. Es ändert sich lediglich die Art und Weise, wie die Daten zwischen einem Client und Server ausgetauscht werden.
HTTP/2 soll die alten HTTP-Version 1.0 und 1.1 nicht ablösen, sondern als Alternative dienen und hauptsächlich die Datenübertragung für bestimmte Anwendungen beschleunigen.
HTTP/3
Der Nachfolger HTTP/3 kombiniert die einzelnen Funktionen von HTTP, TLS und TCP zu einem Protokoll und verzichtet dabei auf die strikte Trennung der Protokolle im OSI-Schichtenmodell. In Kombination mit QUIC ist HTTP/3 insgesamt schneller, kann besser mit Paketverlusten und dem Netzwechsel mit Adresswechsel des Clients umgehen, was bei der mobilen Nutzung eine große Rolle spielt.
HTTP-Adressierung
Damit der Server weiß, was er dem HTTP-Client schicken soll, adressiert der HTTP-Client eine Datei, die sich auf dem HTTP-Server befinden muss. Dazu wird vom HTTP-Client ein URL (Uniform Resource Locator) im HTTP-Header an den HTTP-Server übermittelt:
http://Servername.Domainname.Top-Level-Domain:TCP-Port/Pfad/Datei
z. B. http://www.elektronik-kompendium.de:80/sites/kom/0902231.htm
Der URL besteht aus der Angabe des Transport-Protokolls "http://". Dann folgt der Servername (optional) und der Domainname mit anschließender Top-Level-Domain (TLD). Die Angabe zum TCP-Port ist optional und nur erforderlich, wenn die Verbindung über einen anderen Port, als dem Standard-Port 80 abgewickelt wird. Pfade und Dateien sind durch den Slash "/" voneinander und von der Server-Adresse getrennt. Folgt keine weitere Pfad- oder Datei-Angabe schickt der Server die Default-Datei der Domain. Sind Pfad und/oder Datei angegeben, schickt der HTTP-Server diese Datei zurück. Ist diese Datei nicht existent, versucht er es mit einer Alternative. Gibt es keine, wird die Standard-Fehlerseite (Error 404) an den HTTP-Client übermittelt.
HTTP-Cookie
Cookies („Kekse“) sind in HTTP eine Möglichkeit, mit dem der Webserver im HTTP-Response den Browser anweisen kann, Daten lokal zu speichern. Führt der Browser einen erneuten HTTP-Request zum selben Webserver aus, dann schickt der Browser die Daten in den dazugehörigen Cookies mit.
Der Grund, warum es Cookies gibt ist, dass es sich bei HTTP um ein zustandsloses Protokoll handelt. Das heißt, ein Webserver kann im Prinzip zwischen mehreren HTTP-Requests vom selben Client keinen Zusammenhang herstellen. Die Requests werden unabhängig voneinander verarbeitet. Für den reinen Informationsabruf ist das auch völlig ausreichend. Wenn man aber Webseiten anwendungsorientiert gestalten will, dann muss man zwischen den HTTP-Requests mehrerer Clients unterscheiden können. Zum Beispiel den Warenkorb in einem Online-Shop. Dazu wird im Webserver ein Identifier erzeugt, der in einem Cookie im Browser gespeichert wird. Bei jedem erneuten Request weist sich der Client mit diesem Identifier aus. Auf diese Weise kann der Webserver den Client wiedererkennen und den Seitenabruf mit früheren in Verbindung bringen.
Diese an sich sinnvolle Funktion kann man zum Daten speichern verwenden, beispielsweise um Formularfelder beim nächsten Mal vorab auszufüllen. Allerdings eignen sich Cookies auch zum Tracking, also Benutzererkennung. Legitim ist das zum Beispiel bei Webseiten mit Benutzeranmeldung (mit einem First-Party-Cookie). Allerdings gibt es auch seitenübergreifendes Tracking, bei denen nicht der eigentliche Webseiten-Betreiber trackt, sondern externe Diensteanbieter (Third-Party-Cookie), die der Webseiten-Betreiber für den Betrieb seiner Webseite nutzt. Problematisch ist das deshalb, weil das Tracking im Hintergrund erfolgt und man als Webseiten-Besucher davon nichts mitbekommt. Bei jedem Seitenabruf fallen Daten an, auch wenn es nur darum geht, welche Seiten besucht wurden. In Summe entsteht von jedem Webseiten-Besucher ein Profil, welches auch die Besuche von anderen Webseiten miteinschließt. Das dabei entstehende Profil wird dann in der Regel dazu genutzt, für den jeweiligen Besucher maßgeschneiderte Werbung einzublenden.
Das Problem mit den Cookies ist nicht die Cookies selber, sondern was damit gemacht wird. Leider kann man das als Internet-Nutzer nicht erkennen, weshalb das generelle Blockieren von Cookies eine legitime Gegenmaßnahme ist. Nur leider funktionieren dann viele Webseiten nicht mehr, weil sie tatsächlich auf die Cookie-Funktion angewiesen sind. Dazu zählen Online-Shopping, Online-Banking und Online-Communities.
HTTP-Authentifizierung
Manche Informationen und Daten auf einem Webserver sind nicht für jedermann bestimmt und sollen nur einer begrenzten Zahl von Personen zugänglich sein. Dazu gibt es das Basic-HTTP-Authentication-Schema, das einen Benutzernamen und ein Passwort für die Authentifizierung verwendet.
Der Ablauf der Authentifizierung beginnt mit einem normalen HTTP-Request durch den HTTP-Client. Ist der Zugriff auf das angefragte Verzeichnis durch Basic-HTTP-Authentication beschränkt, sendet der HTTP-Server den HTTP-Response mit einem WWW-Authentication-Header-Feld und dem Status-Code 401 (Nicht autorisiert). Der HTTP-Client wird damit zum Senden von Benutzernamen und Passwort aufgefordert. Der HTTP-Client öffnet dann ein Fensterchen, das den Benutzer zur Eingabe von Benutzername und Passwort auffordert. Nach abgeschlossener Eingabe schickt der HTTP-Client die Zugangsdaten an den Server. Sind die Daten korrekt, wird der Zugriff auf die angeforderten Inhalte freigegeben und vom Server ausgeliefert. Bei jedem erneuten HTTP-Request werden die Anmeldedaten erneut vom Client an den Server übermittelt.
Sind die Zugangsdaten inkorrekt, hat der Benutzer mehrmals die Möglichkeit für eine korrekte Eingabe zu sorgen. Gehen diese Anfragen alle schief, wird ein Status-Code von 403 und einer entsprechenden HTML-Datei vom Server geschickt, die den Besucher auf den fehlerhaften Zugriff des passwortgeschützten Bereichs hinweist.
Der Authentifizierungsvorgang mit Basic-HTTP-Authentication ist alles andere als sicher. Die Anmeldedaten werden in Klartext und damit protokollierbar und abhörbar übertragen. Um diese Schwäche zu vermeiden empfiehlt sich das Digest Access Authentication. Dieses benutzt mehrere Parameter zur Verschlüsselung.
HTTP-ABR - HTTP Adaptive Bit Rate
HTTP-ABR ist ein Verfahren, um Videostreaming per HTTP zu übertragen. Eigentlich ist HTTP ein Kommunikationsprotokoll, dass einzelne Dateien überträgt, die irgendwann vollständig übertragen sind. Beim Videostreaming findet eine Ende der Übertragung erst sehr viel später statt. Hier gibt es im Prinzip kein Ende, es sei denn Sender und Empfänger beenden die Verbindung.
Beim Videostreaming kommen jedoch noch weitere besondere Anforderungen zum Tragen, um dem Nutzer das multimediale Erlebnis so angenehm wie möglich zu machen.
Die Anforderungen an das Video-Material können je nach Teilnehmer seht unterschiedlich sein. So kann die Bildschirmgröße von Smartphone bis Full-HD-TV reichen. Und die Bandbreite von vielleicht 100 kBit/s bis 100 MBit/s. Konsequenterweise müsste der HTTP-Server die unterschiedlichen Qualitäts- und Geschwindigkeitsanforderungen berücksichtigen. Mit HTTP-ABR lässt sich die Übertragungsrate an die verfügbare Bandbreite und unterschiedliche Auflösungen anpassen. Dazu ist auf beiden Seiten ein HTTP-ABR-fähiger Client bzw. Server notwendig.
Neben dem normalen HTTP-ABR gibt es noch verschiedene propritäre Varianten.
- HLS von Apple
- HSS von Microsoft
- HDS von Adobe
- MPEG-DASH (Dynamic Adaptive Straming over HTTP), ISO-Standard
Eigenen Webserver einrichten
Für den Raspberry Pi gibt es verschiedene Webserver. Am einfachsten ist es mit dem "lighttpd". Hier muss man am wenigsten konfigurieren und die Installation ist effektiv mit einem Befehl auf der Kommandozeile erledigt.
Übersicht: HTTP
- WWW - World Wide Web
- HTTP/1.1 - HTTP-Kommunikation (Version 1.0/1.1)
- HTTP/2 - HTTP Version 2.0
- HTTP/3 - HTTP Version 3.0
- WebDAV - Web-based Distributed Authoring and Versioning
- HTTPS / HTTP Secure
Weitere verwandte Themen:
- URL - Uniform Resource Locator
- TLS - Transport Layer Security
- DNS - Domain Name Service
- MIME-Typen - Multipurpose Internet Mail Extensions
- Protokolle in der Netzwerktechnik
Lernen mit Elektronik-Kompendium.de
Noch Fragen?
Bewertung und individuelles Feedback erhalten
Aussprache von englischen Fachbegriffen

Netzwerktechnik-Fibel
Alles was du über Netzwerke wissen musst.
Die Netzwerktechnik-Fibel ist ein Buch über die Grundlagen der Netzwerktechnik, Übertragungstechnik, TCP/IP, Dienste, Anwendungen und Netzwerk-Sicherheit.
Netzwerktechnik-Fibel
Alles was du über Netzwerke wissen musst.
Die Netzwerktechnik-Fibel ist ein Buch über die Grundlagen der Netzwerktechnik, Übertragungstechnik, TCP/IP, Dienste, Anwendungen und Netzwerk-Sicherheit.
Artikel-Sammlungen zum Thema Netzwerktechnik
Alles was du über Netzwerktechnik wissen solltest.



