Parallelisierung (Prozessortechnik)
Lange Zeit war es üblich, dass man die Verarbeitungsgeschwindigkeit eines Prozessors hauptsächlich durch das Erhöhen der Taktfrequenz gesteigert hat. Leider ist dem physikalische Grenzen gesetzt, weshalb die Taktrate eines Prozessors nichts über dessen Leistungsfähigkeit aussagt. Außerdem gibt es bei der Ausführung von Programmcode immer wieder zu Verzögerungen. Zum Beispiel beim Zugriff auf den Speicher oder auf Geräte. In so einem Fall ist der Prozessor mit Warten beschäftigt. Er macht erst dann im Programmcode weiter, wenn die Daten aus dem Speicher oder einer Schnittstelle in die Register geladen wurden. Diese Wartezeit führt dazu, dass ein Großteil der zur Verfügung stehenden Rechenleistung überhaupt nicht genutzt wird. Deshalb haben sich die Prozessor-Entwickler schon sehr früh überlegt, wie sie einen Prozessor intern so strukturieren müssen, damit er im Programmcode weitermachen kann, während Daten von außen geladen werden. Das hat dazu geführt, dass Entwickler von Betriebssystemen und auch Anwendungen die anstehenden Berechnungen so programmieren, dass sie parallel verarbeitet werden können, um sie auf viele parallel arbeitende Einheiten verteilen zu können.
Ebenen der Parallelität/Parallelisierung
Die folgenden technischen Lösungen führen tatsächlich dazu, dass Programme parallel ausgeführt werden und nicht nur durch geschicktes Verschachteln und hoher Ausführungsgeschwindigkeit eine gefühlte Parallelität entsteht (Quasiparallelität).
- Pipelining
- Multi-Threading
- Coprozessor
- Multi-Core-Prozessor
- Multi-Prozessor
- Multi-Computer
- Grid / Cloud Computing
Pipelining
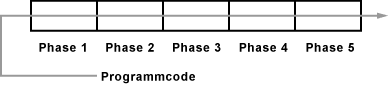
Beim Pipelining erfolgt die Befehlsausführung wie an einem Fließband (Pipeline). Eine Pipeline ist eine Abfolge von Verarbeitungseinheiten, die einen Befehl ausführen. Dabei wird die Ausführung eines Befehls in verschiedene Phasen eingeteilt. Für jede Phase gibt es eine Ausführungseinheit. Wenn ein Befehl von Phase 1 seiner Bearbeitung in Phase 2 tritt, betritt der nächste Befehl Phase 1. Je mehr Phasen oder Stufen eine Pipeline hat, desto mehr Befehle können parallel verarbeitet werden. Eine weitere Parallelisierung ist dadurch möglich, dass man mehrere Pipelines hat oder für bestimmte Pipeline-Stufen mehrere Ausführungseinheiten.
Coprozessor

Der Coprozessor ist ein spezieller Prozessor, der den Hauptprozessor (CPU) um bestimmte Funktionen erweitert und ihn bei bestimmten Rechenaufgaben entlastet. Der Coprozessor beschleunigt dadurch das ganze System. Im Lauf der Zeit wurden viele Funktionen klassischer Coprozessoren in den Hauptprozessor integriert. Beispielsweise Gleitkommaeinheiten und kryptografische Berechnungen.
Multi-Threading

Mit Multi-Threading ist die Fähigkeit eines Prozessors gemeint, der mehrere Programmabläufe (Threads) vorhalten kann und wechselweise bei der Ausführung hin und her schalten kann. Wenn ein Thread auf Speicherzugriffe warten muss, dann wird einfach in einem anderen Thread weitergemacht.
Leider lassen sich nicht alle Aufgaben gleich gut parallelisieren. Es kommt eben auch vor, dass ein Thread auf einen anderen warten muss. Algorithmen, die sich schlecht parallelisieren lassen oder schlecht parallelisiert sind, vergeuden die Zeit mit aufwendigen Abgleichprozeduren. Erschwerend sind die vielen Engstellen im System. Zum Beispiel Schnittstellen- und Massenspeicherzugriffe.
Für den Programmierer ist nicht immer ersichtlich, welche Funktionen sich für die Auslagerung in einen eigenen Thread eignen. Das Parallelisieren von Funktionen verlangt vom Programmierer eine völlig andere Denkweise. In Echtzeitstrategiespielen könnte die Spielelogik unabhängig von der grafischen Ausgabe und der Eingabeverarbeitung arbeiten. Bei der Bildbearbeitung lohnt es sich zum Beispiel aufwendige Berechnungen in einen eigenen Thread zu verlagern. So bleibt der Zugriff auf das Programm für den Nutzer möglich. Doch nicht immer kann das so umgesetzt werden. So wird ein Großteil der Berechnungen von der Grafikkarte selbst ausgeführt.
Die Entwicklung von Multi-Threading war deshalb wichtig, weil es eine Vorstufe der Multi-Core-Technik ist. Durch Multi-Threading konnte eine neue Generation von Software-Entwicklern auf die Nutzung von Mehrkern-Prozessoren vorbereiten.
Beispiel: SMT - Simultanes Multi-Threading (Intel)
Simultanes Multi-Threading bedeutet, dass mehrere Threads gleichzeitig abgearbeitet werden. Ein Thread ist ein Code-Faden bzw. ein Programmablauf. Wartet ein Thread auf Daten aus dem Speicher, dann wird auf einen anderen Thread umgeschaltet, der die freien Ressourcen weiterverwendet.
SMT ist deshalb sinnvoll, weil ein Thread alleine die ganzen Funktionseinheiten in einem Prozessor überhaupt nicht auslasten kann. Die Auslastung ist bei zwei gleichzeitig ablaufenden Threads wesentlich besser. Außerdem sind die Ausführungspfade unterschiedlicher Threads unabhängig voneinander. Sie kommen sich nur sehr selten in die Quere.
Weil SMT relativ gut funktioniert kann man auf die Out-of-Order-Technik verzichten. Das macht sich insbesondere beim Energieverbrauch bemerkbar. Single-Thread-Prozessoren mit SMT verbrauchen einfach weniger Leistung.
Beispiel: Hyper-Threading (Intel)
Hyper-Threading ist eine Entwicklung von Intel und eine Vorstufe zum Multi-Core-Prozessor. Hyper-Threading gaukelt dem Betriebssystem einen zweiten Prozessorkern vor, um dadurch die Funktionseinheiten besser auszulasten und Wartezeiten von Daten aus dem Speicher zu überbrücken.
Wenn ein Thread des Prozessors auf Daten aus dem Speicher warten muss, dann kann der Prozessor einen zweiten Thread nutzen, um an einer anderen Stelle im Programmcode weiter zu machen. Wenn ein genügend großer Cache und ein gutes Prefetching vorhanden sind, dann stehen die Chancen gut, dass die Wartezeit sinnvoll überbrückt werden kann.
Prefetching ist ein Verfahren, bei dem Befehle und Daten vorab geladen und manchnmal sogar spekulativ ausgeführt werden.
Der zusätzliche Hardware-Aufwand für Hyper-Threading liegt bei 20 Prozent und kann 40 bis 50 Prozent Geschwindigkeitsgewinn bringen.
Multi-Core-Prozessor
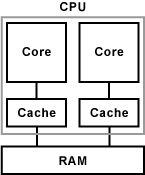
Bei der Multi-Core- bzw. Mehrkern-Technik sind in einem Prozessor (CPU) mehrere Kerne (Core) zusammengeschaltet. Das bedeutet, moderne Prozessoren haben nicht nur eine Recheneinheit, sondern mehrere. Man bezeichnet diese Prozessoren als Multi-Core- oder Mehrkern-Prozessoren. Rein äußerlich unterscheiden sich Multi-Core-CPUs nicht von Single-Core-CPUs. Innerhalb des Betriebssystems wird der Multi-Core-Prozessor wie mehrere Recheneinheiten behandelt. Je nach Anzahl der Kerne gibt es abgewandelte Bezeichnungen, die darauf hindeuten, wie viele Kerne im Prozessor integriert sind. Zum Beispiel Dual-Core für zwei Rechenkerne und Quad-Core für vier Rechenkerne.
Multi-Prozessor-System
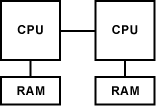
Seit Anfang der 1990er Jahre gibt es in Supercomputern mehrere Prozessoren mit eigenem Arbeitsspeicher. Diese Systeme werden als Multi-Prozessor-Systeme bezeichnet. In Personal Computern haben sich mehrere Prozessoren nicht durchgesetzt. Hier dominieren Multi-Core-Prozessoren.
Grid / Cloud-Computing

Die Vernetzung von Computersystemen zur parallelen Berechnung und Verarbeitung von Daten bezeichnet man als Grid. Häufig wird das Grid auch als Cloud bezeichnet. Man spricht dann von Cloud Computing.
Weitere verwandte Themen:
- Prozessor (CPU)
- Prozessortechnik
- Prozessor-Architektur
- Virtualisierung
- GPGPU - General Purpose Computation on Graphics Processing Unit
Lernen mit Elektronik-Kompendium.de
Noch Fragen?
Bewertung und individuelles Feedback erhalten
Aussprache von englischen Fachbegriffen

Computertechnik-Fibel
Computertechnik neu verstehen - jetzt in der 6. Auflage
Die Computertechnik-Fibel ist in einer vollständig überarbeiteten 6. Auflage als Buch, eBook und Bundle erschienen.
Statt einzelne Teile zu lernen, entwickelst du ein Gesamtverständnis moderner Computersysteme. Von der Hardware, Betriebssysteme, Virtualisierung, KI und Quantencomputer.
inkl. MwSt. zzgl. Versandkosten

Computertechnik-Fibel
Alles was du über Computertechnik wissen musst.
Die Computertechnik-Fibel ist ein Buch über die Grundlagen der Computertechnik, Prozessortechnik, Halbleiterspeicher, Schnittstellen, Datenspeicher, Laufwerke und wichtige Hardware-Komponenten.
Artikel-Sammlungen zum Thema Computertechnik
Alles was du über Computertechnik wissen solltest.



