Pipelining (Prozessor-Technik)
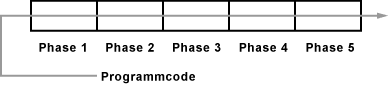
Pipelining bedeutet, dass Befehle im Programmcode nicht an einem Stück, sondern in mehreren Schritten, wie an einem Fließband abgearbeitet werden. Wobei jede Station im Fließband für eine bestimmte Aufgabe zuständig ist. Eine Pipeline ist eine Reihe von Verarbeitungseinheiten, die einen Befehl nacheinander bearbeiten, bis seine Ausführung abgeschlossen ist und ein Ergebnis ausgegeben werden kann.
Wenn ein Befehl von Phase 1 seiner Bearbeitung in Phase 2 tritt, betritt der nächste Befehl Phase 1. Während ein Befehl in der Pipeline verarbeitet wird, wird bereits der nächste Befehl zur Verarbeitung nachgeschoben. Die Bearbeitung in jeder Phase dauert im Optimalfall einen Taktzyklus.
Die Pipeline-Verarbeitung kommt typischerweise in CPUs zum Einsatz, wo die Befehle so komplex sind, dass ihre Bearbeitung innerhalb eines Taktzyklusses nicht möglich ist. Durch die Bearbeitung über mehrere Takte und Schritte können mehrere Befehle innerhalb der Pipeline gleichzeitig verarbeitet werden. Indem verschiedene Befehle gleichzeitig in unterschiedlichen Phasen der Verarbeitung bearbeitet werden, wird die Auslastung der Ressourcen maximiert. Durch die Optimierung der Pipeline kann die Gesamteffizienz und Leistung der CPU weiter erhöht werden.
Bei einer langen Pipeline können sich aber längere Wartezeiten ergeben. Zum Beispiel beim Speicherzugriff. Durch Programmcode-Optimierungen lassen sich Wartezeiten reduzieren.
Beispiel für eine 5-Phasen-Pipeline
- Fetch: Befehl holen/laden
- Decode: Befehl dekodieren
- Load: Operanden laden
- Execute: Befehl ausführen
- Write: Ergebnis schreiben
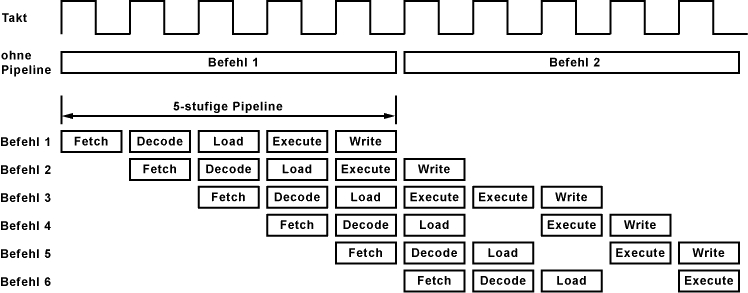
Im oberen Beispiel besteht die Pipeline zur Befehlsbearbeitung aus 5 Stufen bzw. Phasen. Innerhalb der Pipeline wird versucht alle Stufen gleichzeitig für aufeinanderfolgende Befehle zu nutzen. In diesem Beispiel benötigt der dritte Befehl zwei Taktzyklen für die Execute-Phase. Die nachfolgenden Befehle müssen warten. Die Bearbeitung in der Pipeline kommt ins Stocken.
Bei Desktop-Prozessoren ist es üblich, die Pipeline zu verlängern.
Doch weniger Pipeline-Stufen haben insbesondere dann einen Vorteil, wenn im Programmcode häufig unvorhergesehene Sprünge zu einer anderen Stelle im Programmcode erfolgen. Bei einem Sprung im Programmcode muss eine Pipeline komplett geleert werden. Die bereits erfolgten Berechnungen sind überflüssig. In einer langen Pipeline wären das sehr viele Berechnungen. In einer kurzen Pipeline macht ein unvorhergesehener Sprung nicht so viel aus. Um trotzdem eine lange Pipeline realisieren zu können, setzt man auf eine spekulative Sprungvorhersage. Die Sprungvorhersage könnte zum Beispiel ein Teil einer vorgelagerten Pipeline sein.
Superskalarität

Zur Bearbeitung eines Befehls ist meistens nur eine bestimmte Einheit eines Prozessors beschäftigt. Andere Einheiten bleiben ungenutzt. Wenn die Befehle eines Programms in geeigneter Reihenfolge auf zwei oder mehr Pipelines aufgeteilt werden und diese unabhängig voneinander arbeiten (skalar) können, entsteht eine parallele Ausführung.
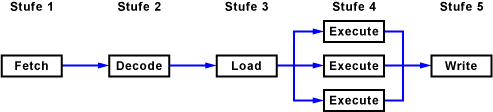
Sind von einer Ausführungseinheit gleich mehrere vorhanden, spricht man von Superskalarität.
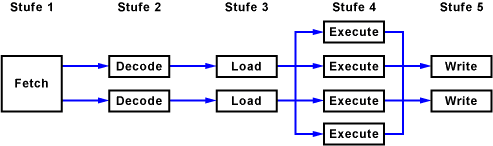
Moderne Prozessoren verwenden meist eine Kombination aus mehreren Pipelines und Ausführungseinheiten.
Beispiel für eine Pipeline mit L1- und L2-Cache
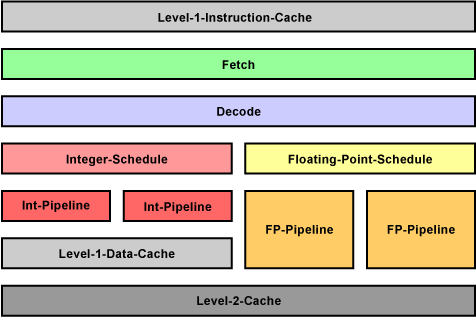
In-Order-Execution
Bei der In-Order-Execution werden die Befehle in der Reihenfolge abgearbeitet, wie es der Programmierer im Programmcode festgelegt hat.
Mit einfachen Heuristiken prüft der Prozessor, ob zwei aufeinanderfolgende Befehle parallel ausgeführt werden können. Das ist dann der Fall, wenn sie nicht voneinander abhängig sind. Wenn möglich werden sie in zwei Pipelines abgearbeitet. Für spezielle Befehlsgruppen kann es sogar eigene Pipelines geben. Wenn ein Befehl früher fertig ist als der Befehl in der anderen Pipeline, dann wartet er, bis auch der andere abgearbeitet ist. Erst dann geht es im Programmcode weiter.
Der Compiler kann schon beim Übersetzen des Programmcodes in die Maschinensprache des Prozessors durch geschicktes Sortieren der Befehle für eine Optimierung sorgen. Wenn dann aber ein Befehl auf den Speicher zugreift und die Daten nicht in einem der Caches liegen, dann muss der Prozessor warten. An dieser Stelle hätte eine Out-of-Order-Execution klare Vorteile. Hier treten Wartezeiten seltener auf.
Out-of-Order-Execution
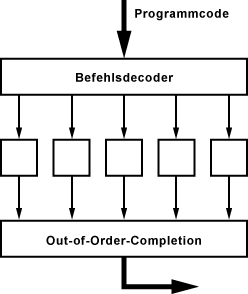
Bei der Out-of-Order-Execution können die Befehle vom Prozessor selber vor der Ausführung umsortiert werden. Zum Beispiel dann, wenn noch Daten nachgeladen werden müssen und es aufgrund dessen für die Recheneinheiten zu Wartezeiten kommen würde. Dabei können die Recheneinheiten besser ausgelastet werden.
Bei superskalaren Prozessoren, mit mehreren Pipelines, ist die Geschwindigkeitssteigerung im wesentlichen von der Auslastung der parallel arbeitenden Ausführungseinheiten abhängig. Dabei versucht der Befehlsdecoder den Programmcode auf mehrere Pipelines oder Ausführungseinheiten zu verteilen.
Bei der Out-of-Order-Execution werden die Abhängigkeiten zwischen den Befehlen aufgelöst, um die Berechnungen dann mehrfach parallel im Rechenwerk auszuführen.
Falls der Prozessor mit der Ausführung eines Befehls warten muss, etwa auf Daten aus dem Arbeitsspeicher, verarbeitet er einen anderen Befehl, der eigentlich erst später an der Reihe kommen würde. Er arbeitet die Befehle nicht in der Reihenfolge ab, wie sie im Programmcode stehen (In Order), sondern in einer optimierten Reihenfolge (Out of Order).
Da die Ausführungseinheiten mit den einzelnen Befehlen unterschiedlich lange beschäftigt sind, kommen die Ergebnisse der Berechnungen in einer anderen Reihenfolge, als die Befehle im Programmcode. Die Out-of-Order-Completion bringt mit einem Reorder Buffer (ROB) die Rechenergebnisse in die Reihenfolge, die der Programmierer ursprünglich vorgesehen hat.
Branch Prediction und Speculative Execution
Richtig effizient ist die Out-of-Order-Execution erst dann, wenn sie den Programmcode spekulativ ausführen kann. Das ist dann sinnvoll, wenn der Prozessor Rechenwerke frei hat. Weil ein Programmcode Bedingungen enthält, wodurch sich der Ablauf im Programmcode verzweigen kann (Branching), muss er spekulieren. Eine Sprungvorhersageeinheiten versucht, die vermutlich als Nächstes wichtigen Speicheradressen zu erraten (Branch Prediction). Die Sprungvorhersage beruht im einfachsten Fall auf statistischen Erkenntnissen. Beispielsweise finden Rückwärtssprünge im Programmcode oft am Ende von Schleifen statt.
Dadurch kann der Prozessor Befehle schon einmal auf Verdacht ausführen (Speculative Execution), um später das Ergebnis schneller verfügbar zu haben. Trifft die Sprungvorhersage zu, dann hat das einen regelrechten Geschwindigkeitsschub zur Folge. Trifft die Sprungvorhersage nicht zu, dann muss der Prozessor die Ergebnisse verwerfen.
Die Hardware für die Sprungvorhersage verbraucht leider sehr viel Energie. Außerdem kann Out-of-Order-Execution, Branch Prediction und Speculative Execution zu Sicherheitslücken in Prozessoren führen.
Sicherheitslücke in Intel-, AMD- und ARM-Prozessoren
Im Jahr 2017 wurden Sicherheitslücken mit der Bezeichnung Spectre und Meltdown vor allem in Prozessoren von Intel, aber auch ARM und teilweise AMD bekannt, die es bösartiger Software erlaubte, vermeintlich geschützte Daten eines anderen parallel laufenden Programms zu lesen. Besonders betroffen davon sind die Betreiber virtueller Maschinen mit unterschiedlichen Kunden, die davon ausgehen, dass die emulierten Systeme voneinander abgeschottet sind. Anders bei typischen Desktop-PCs. Hier gibt es andere Sicherheitslücken, die sich leichter für Angriffe missbrauchen lassen.
Weitere verwandte Themen:
- Multi-Core / Mehrkern-Prozessoren
- Prozessor (CPU)
- Prozessortechnik
- Prozessor-Architektur
- Cache (L1 / L2 / L3)
Lernen mit Elektronik-Kompendium.de
Noch Fragen?
Bewertung und individuelles Feedback erhalten
Aussprache von englischen Fachbegriffen

Computertechnik-Fibel
Computertechnik neu verstehen - jetzt in der 6. Auflage
Die Computertechnik-Fibel ist in einer vollständig überarbeiteten 6. Auflage als Buch, eBook und Bundle erschienen.
Statt einzelne Teile zu lernen, entwickelst du ein Gesamtverständnis moderner Computersysteme. Von der Hardware, Betriebssysteme, Virtualisierung, KI und Quantencomputer.
inkl. MwSt. zzgl. Versandkosten

Computertechnik-Fibel
Alles was du über Computertechnik wissen musst.
Die Computertechnik-Fibel ist ein Buch über die Grundlagen der Computertechnik, Prozessortechnik, Halbleiterspeicher, Schnittstellen, Datenspeicher, Laufwerke und wichtige Hardware-Komponenten.
Artikel-Sammlungen zum Thema Computertechnik
Alles was du über Computertechnik wissen solltest.



