Künstliche neuronale Netze (KNN)
Künstliche neuronale Netze, kurz KNN, oder englisch Artificial Neural Network, kurz ANN, sind Verbindungen zwischen künstlichen Neuronen, die in Schichten organisiert sind und deren Funktionsweise von den Neuronen im Gehirn inspiriert sind.
Es gibt also tatsächlich biologische Neuronen. Das sind echte Nervenzellen in unserem Gehirn, von denen es etwa 86 Milliarden gibt und die miteinander verbunden sind.
Seit den 1950er-Jahren existiert der Begriff "neuronale Netze". Damals haben Forscher entdeckt, dass die Neuronen im Gehirn unterschiedlich gewichtete Eingabeimpulse bekommen und daraus einen Ausgabeimpuls erzeugen, der wieder anderen Neuronen als Eingabe dient.
Computerwissenschaftler haben versucht, diese recht primitive Idee aus der Hirnforschung mit der damaligen Technik durch Matrixberechnungen nachzuprogrammieren. Heute haben künstliche neuronale Netze nichts mehr mit der Hirnforschung zu tun. Aus Informatiksicht sind neuronale Netze nur eine Verkettung von Funktionen, deren Parameter sich über immer neue Eingabedaten anpassen lassen.
Wenn ein Mathematiker von einer Matrix spricht, ist das für einen Programmierer ein zweidimensionales Array. Vereinfacht ausgedrückt eine Tabelle mit zwei Spalten. In der KI spricht man dann von einem Tensor der Stufe zwei. Ein Array mit drei Spalten wäre ein Tensor der Stufe drei. Und so weiter.
Der Begriff "Tensor" bezeichnet ein mathematisches Objekt der linearen Algebra und Differenzialgeometrie.
Aufbau eines neuronalen Netzes
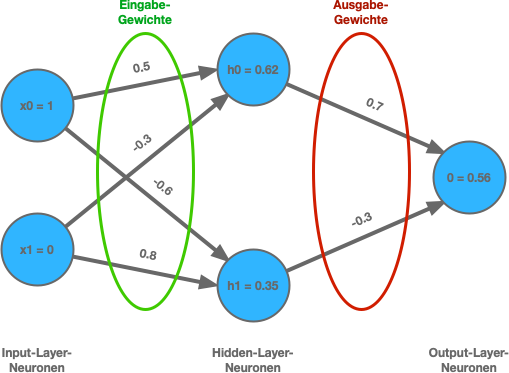
Ein neuronales Netz besteht aus vielen unterschiedlichen Schichten mit Neuronen. Zwischen der Eingabe- und Ausgabeschicht gibt es je nach Netz viele versteckte Schichten. Die Neuronen sind dabei mit allen Neuronen auf der nächsten Schicht miteinander verknüpft, wodurch es viele Millionen Verbindungen mit dazugehörigen Parametern (Gewichte) geben kann.
Jedes Neuron führt eine einfache Berechnung durch und leitet das Ergebnis an alle Neuronen der nächsten Schicht weiter. In Summe können komplexe Zusammenhänge erlernt oder Entscheidungen getroffen werden.
Diese Eigenschaften machen es äußerst schwierig nachzuvollziehen, wie genau diese Systeme Entscheidungen treffen. Deshalb funktionieren KI-Modelle oft wie eine „Black Box“.
Woher weiß man, wie viele Schichten und Neuronen ein neuronales Netz braucht?
Man weiß nicht exakt im Voraus, wie viele Schichten und Neuronen ein neuronales Netz braucht. Das hängt stark von der Komplexität der Aufgabe, der Datenmenge und dem Ziel ab. Die optimale Struktur muss man meistens experimentell durch Testen, Validieren und Anpassen herausfinden. Außerdem gibt es einige Faustregeln und Strategien, unterstützt durch Erfahrung und das Anwenden automatisierter Methoden und Tools.
Anfangs wird man die Anzahl der Schichten und Neuronen anhand der Aufgabe definieren. Bei einfachen Aufgaben für eine lineare Klassifikation können 1 bis 2 Schichten mit wenigen Neuronen genügen. Komplexe Aufgaben, zum Beispiel Bilderkennung und Spracherkennung, bedarf es tiefe Netze mit vielen Schichten und Neuronen. Hier startet man mit einem vergleichsweise einfachen Modell mit mehreren versteckten Schichten (Hidden Layer) mit je 16 bis 128 Neuronen. Dann wendet man auf dieses Modell die Trainingsdaten und anschließend die Testdaten an.
- Zu wenig Neuronen/Schichten erkennt man daran, dass das Modell nicht lernt und auch nach vielen Epochen der Fehler nicht kleiner wird. Man nennt das Underfitting. Das Netz ist einfach zu klein, um die Varianz in den Datensätzen in sich aufzunehmen. Dann sollte man mehr Neuronen oder weitere Schicht hinzufügen. Aber, Underfitting muss nicht zwangsläufig an zu wenig Neuronen oder Schichten liegen.
- Bei zu vielen Neuronen/Schichten lernt das Modell die Trainingsdaten zu gut. Statt Muster zu erkennen und diese zu lernen, lernt es die Trainingsdaten auswendig und generalisiert schlecht auf neue Daten. Man merkt das daran, dass trotz weiterem Training die Leistung nicht besser wird. Man nennt das dann Overfitting. Dann muss man Neuronen und Schichten entfernen oder mit mehr und unterschiedlichen Daten trainieren. Aber, Overfitting muss nicht zwangsläufig an zu vielen Neuronen oder Schichten liegen.
Unterschiede zum klassischen Programmieren

Bei der klassischen Programmierung legt ein Programmierer die Funktionen fest, anhand der die Software die Eingabe-Daten in Ausgabe-Daten umwandelt oder berechnet. Hier gilt die goldene Regel, dass die gleichen Eingabe-Daten immer zu den gleichen Ausgabe-Daten führen. Das Ergebnis ist immer reproduzierbar und ganz wichtig, der Weg zum Ziel ist bekannt. Wenn wir eine Liste von Zahlen addieren kommt immer ein korrektes mathematisches Ergebnis heraus.

Bei einem KI-Modell, im Sinne einer Software, ist das anders. Hier gibt der KI-Entwickler keine festen Regeln (wie Wenn-Dann) vor, sondern gestaltet zum Beispiel ein neuronales Netz, indem er die Anzahl der Schichten und Neuronen festlegt, die Anfangswerte der Verbindungen definiert und Trainingsdaten bereitstellt.
Die „Logik“ des neuronalen Netzes entsteht durch Training mit den Daten, nicht durch vorgegebene Programmierung. Ein weiterer Unterschied ist, dass die Daten-Ausgabe dann nur eine Annäherung an das richtige Ergebnis ist. Während dem Training führen gleiche Eingabe-Daten wegen dem Einfluss der Ausgabe-Daten auf die Gewichte der Neuronen-Verbindungen, immer zu anderen Ausgabe-Daten. Das ist der Kern des maschinellen Lernens, bei dem das neuronale Netz die Zusammenhänge und Muster aus den Trainingsdaten lernt. Es ist ein bisschen wie bei einem selbstregulierenden System.
Interessant ist das dann, wenn ein Programmierer aus einer großen Menge und Varianz der Eingabe-Daten keinen allgemein gültigen Algorithmus ableiten kann. In diesem Fall kann das Training eines neuronalen Netzes nützlich sein, dessen Automatismus sich selbst Zusammenhänge und Muster erarbeiten kann.
Neuronale Netztypen (Auszug)
Grundsätzlich unterscheiden sich die Typen in der Regel durch die unterschiedlichen Netztopologien und Verbindungsarten, so zum Beispiel einschichtige, mehrschichtige, Feedforward- oder Feedback-Netze.
- Convolutional Neural Networks (CNN)
- Recurrent Neural Networks (RNN)
- Transformer-Modelle (GPT)
- Generative Adversarial Networks (GAN)
- ...
Trainingsdaten
Künstliche neuronale Netze müssen für die Erfüllung von Aufgaben trainiert werden. Dazu müssen die Trainingsdaten in der Regel groß genug und vielfältig sein, was in vielen Fällen eine Herausforderung darstellt.
Ein häufiges Problem liegt in der Qualität der Trainingsdaten. Wenn diese nicht gut ausgewählt sind, kann das neuronale Netz nicht die notwendigen Fähigkeiten entwickeln, um die gestellten Aufgaben zu lösen.
Entscheidend ist also nicht nur die Menge, sondern auch, dass die Daten repräsentativ und von hoher Qualität sind.
Man braucht also für neuronale Netze eine ausreichend große Trainingsdatenmenge. Aber niemand weiß genau, wie groß die optimale Datenbasis für das Training eines neuronalen Netzes ist. Ein neuronales Netz lernt nur dass, was in den Trainingsdaten enthalten ist. KI muss jedoch auch bei Eingaben, die es so noch nie gesehen hat, gut funktionieren. Deshalb muss man nach dem Training mit einem unabhängigen Testdatensatz die Funktion prüfen.
Training
Beim Training eines künstlichen neuronalen Netzes wird der gesamte Trainingsdatensatz mehrmals durchlaufen. Ein Durchgang wird als Epoche bezeichnet. In der Regel sind zum Lernen mehrere Hundert oder sogar Tausend Epochen notwendig.
Zunächst erfolgt ein Feedforward. Dabei werden die Eingabedaten Schicht für Schicht durch das Netz geleitet, wobei jede Schicht eine Aktivierungsfunktion auf die gewichteten Eingaben anwendet, um die Ausgaben zu berechnen. Diese Berechnung erfolg Schicht für Schicht und Neuron für Neuron. Hardware, die auf die Art der Berechnung optimiert ist und mehrere Berechnungen parallel machen kann, arbeitet schneller.
Anschließend wird der Fehler zwischen der Ausgabe des Netzes und dem zu erwarteten Zielwert ermittelt. Mithilfe der Backpropagation wird dann dieser Fehler rückwärts durch das Netz propagiert. Dabei werden die Gewichte der Verbindungen zwischen den Neuronen angepasst und dadurch der Fehler in der nächsten Epoche reduziert.
Epoche
Die Epoche ist ein spezifischer Fachbegriff im KI-Training, insbesondere beim überwachten Lernen von künstlichen neuronalen Netzen. Eine Epoche bezeichnet einen vollständigen Durchlauf des gesamten Trainingsdatensatzes durch das Netzwerk. Sie hat einen direkten Einfluss auf den Lernfortschritt.
Die Anzahl der Epochen gibt an, wie oft der gesamte Trainingsdatensatz dem neuronalen Netz gezeigt wird. Das ist deshalb notwendig, weil die Gewichte zwischen den Neuronen noch nicht richtig eingestellt sind und deshalb die Fehlerrate sehr hoch ist. Damit die Fehlerrate sinkt, braucht man für das Training sehr viele Daten und der Vorgang muss mehrmals wiederholt werden.
Dabei könnte man denken, je mehr Epochen (Durchläufe) desto besser. Aber nein, mehr Epochen sind nicht automatisch besser. Bei zu vielen Epochen kann das Netz anfangen zu überlernen (Overfitting), was vor allem bei größeren Netzen passieren kann. Es ist dann nicht mehr in der Lage zu generalisieren. Es hat dann die Daten auswendig gelernt.
Ein typischer Lernverlauf über viele Epochen:
- Anfang: Fehler sinkt schnell.
- Mitte: Fehler sinkt langsamer.
- Später: Fehler verändert sich nicht, manchmal kleine Schwankungen.
Zu viele Epochen verlängert das Training und verschwenden Zeit und Rechenleistung.
Ein guter Kompromiss ist den Fehler über Epochen zu beobachten und bei einem stabilen Fehler das Training zu stoppen.
Feedforward (Weiterleitung)
Feedforward bezeichnet den Prozess, bei dem Eingaben durch ein neuronales Netzwerk geleitet werden. Von der Eingabeschicht über verborgene Schichten bis hin zur Ausgabeschicht. Jede Schicht berechnet auf Basis der aktuellen Gewichte und Aktivierungsfunktionen ihren Ausgabewert. Am Ende steht eine Vorhersage oder Ausgabe des Netzwerks.
Feedforward ist ein notwendiger Schritt, um überhaupt zu wissen, wie gut oder schlecht das neuronale Netz gerade arbeitet. Es dient der Berechnung des Fehlers. Das eigentliche Lernen passiert erst bei der Backpropagation, das nach dem Feedforward erfolgt.
Zusammengefasst dient Feedforward der Berechnung von Ausgaben auf Basis gegebener Eingaben.
Aktivierungsfunktion
Eine Aktivierungsfunktion transformiert die Summe der Eingaben eines Neurons in einen nichtlinearen Ausgabewert. Diese Nichtlinearität ermöglicht es dem Netzwerk, komplexe Muster zu lernen. Ein weiterer Vorteil von Aktivierungsfunktionen ist die Begrenzung der Ausgabewerte, beispielsweise zwischen 0 und 1, wie bei der Sigmoid-Funktion. Zudem fördern sie den Lernprozess, da sie eine glatte Ableitung für die Backpropagation bieten.
Erst durch den Einsatz einer Aktivierungsfunktion wird eine flexible und dynamische Informationsverarbeitung im neuronalen Netz möglich.
Backpropagation (Fehlerrückführung)
Die Backpropagation ermöglicht es, die Gewichte der Verbindungen zwischen den Neuronen zu optimieren. Sie berechnet, wie stark jeder Gewichtswert zum Fehler beigetragen hat, und passt diese Gewichte entsprechend an. Der Prozess erfolgt rückwärts durch das Netzwerk, beginnend beim Output über die Hidden-Layer bis hin zum Input.
Diese Methode ist besonders effektiv für das Lernen durch Fehlerkorrektur, da sie darauf abzielt, die Vorhersagen des Netzwerks zu verbessern.
Der Zusammenhang zwischen Feedforward und Backpropagation ist, dass Feedforward Vorhersage macht, aufgrund der der Fehler (Differenz zwischen Vorhersage und Zielwert) berechnet wird. Und die Backpropagation verfolgt Fehler zurück und passt die Gewichte an. Der Vorgang ist vergleichbar mit aus „Fehlern lernen“, wodurch die Leistungsfähigkeit des Netzwerks verbessert wird.
Gewichte der Verbindungen
In einem neuronalen Netz sind die Neuronen miteinander verbunden. Jede dieser Verbindungen hat einen Wert, den man „Gewicht“ nennt. Ein Gewicht bestimmt, wie stark ein bestimmtes Eingangssignal (Input), z. B. ein Sensorwert, den Ausgang (Output) eines Neurons beeinflusst. Jedes Eingangssignal hat also ein Gewicht, dass den Ausgang beeinflusst.
- Je größer das Gewicht, desto stärker wirkt dieser Eingang auf das Ergebnis am Ausgang.
- Je kleiner oder negativer das Gewicht, desto weniger oder gegenteilig wirkt er.
In einem künstlichen Neuron passiert typischerweise Folgendes:
Jeder Eingangswert (Input) wird mit einem zugehörigen Gewicht multipliziert. Dann werden alle gewichteten Eingangswerte aufsummiert. Zuzüglich eines Bias (eine Art Grundwert). Das Ergebnis wird durch eine Aktivierungsfunktion geschickt. Das Resultat ist die Ausgabe (Output) des Neurons.
In der Praxis kann man sich das wie ein Mischpult vorstellen. Die Eingabewerte sind Mikrofone. Die Gewichte sind die Regler für die Lautstärke jedes Mikrofons. Der Summenkanal fasst alles zusammen. Die Aktivierungsfunktion ist ein Verzerrer oder Limiter. Sie sorgt dafür, dass der Ausgabewert z. B. nicht übersteuert.
Ein Gewicht bestimmt, indirekt über die Aktivierungsfunktion, wie stark eine Eingabe die Ausgabe beeinflusst. Dabei gilt, ein kleines Gewicht hat einen geringen Einfluss. Ein hohes Gewicht hat einen großen Einfluss.
Die Gewichte entscheiden, wie das neuronale Netz auf Eingaben reagiert. Sie „programmieren“ das Verhalten des Netzes. Aber nicht durch Programmcode, sondern durch Zahlenwerte.
Beim Training des Netzes werden diese Gewichte angepasst, bis das Netz lernt, bestimmte Eingaben richtig zu klassifizieren bzw. korrektere Vorhersagen (Inference) zu treffen. Das Lernen erfolgt, vereinfacht ausgedrückt, durch das Veränderung der Gewichtung der Signale zwischen den Neuronen.
Nach dem Training enthalten die Gewichte das gelernte Wissen des Netzes. Sie sind das Gedächtnis des neuronalen Netzes. Die Gewichte entstehen durch das Training.
Bias
Der Bias ist ein zentraler Bestandteil bei der Berechnung innerhalb eines künstlichen Neurons. Er ist ein konstanter Wert, der zur gewichteten Summe hinzugefügt wird.
Man kann den Bias aber auch als zusätzlichen Eingang sehen. Dann ist der Bias einfach ein Gewicht mit festem Eingabewert.
Der Bias verschiebt die Aktivierungsfunktion einfach nach oben oder unten. Dabei bestimmt er, wie leicht oder schwer es ist, aktiviert zu werden.
Bei einem großen negativen Bias feuert das Neuron selten. Bei einem großen positiven Bias feuert das Neuron schnell.
Der Bias hat letztlich mehrere komplexe Einflüsse im künstlichen Neuron. Der Bias verschiebt die Aktivierungsfunktion, erhöht die Modellflexibilität und bestimmt die Aktivierungsschwelle des Neurons.
Ohne Bias kann ein neuronales Netz viele Zusammenhänge nicht korrekt modellieren und besonders einfache lineare Verschiebungen nicht lernen.
Ablauf eines Trainings mit einem Beispiel
Wir stellen uns vor, ein künstliches neuronales Netz ist wie eine riesige Gruppe von Freunden, die zusammenarbeiten, um Rätsel zu lösen. Jede Person bekommt ein bisschen Information und teilt diese mit den anderen, bis alle eine Antwort gefunden haben.
Wie das Training abläuft:
- Lernen durch Beispiele: Das neuronale Netz bekommt viele Beispiele gezeigt. Zum Beispiel Bilder von Katzen und Hunden. Zu jedem Bild sagt jemand dem Netzwerk: "Das ist eine Katze" oder "Das ist ein Hund."
- Raten und Fehler machen: Am Anfang rät das neuronale Netz oft falsch, weil es noch nicht viel weiß. Es könnte ein Hund sehen und sagen: "Das ist eine Katze."
- Fehler erkennen und korrigieren: Jedes Mal, wenn das neuronale Netz falsch liegt, bekommt es eine Art Hinweis, der ihm zeigt, wie es beim nächsten Mal besser raten kann. So lernt es Schritt für Schritt.
- Verbindungen anpassen: Die Freunde im neuronale Netz (auch "Neuronen" genannt) passen ihre Verbindungen an, damit sie bessere Antworten geben können. Sie flüstern einander zu: "Beim letzten Mal war das falsch, also probiere ich es diesmal anders."
- Immer besser werden: Je mehr Beispiele das neuronale Netz sieht und je öfter es übt, desto besser kann es das Rätsel lösen.
Am Ende ist das neuronale Netz so gut trainiert, dass es fast immer weiß, ob es eine Katze oder einen Hund sieht – oder was auch immer es gelernt hat.
Grenzen von künstlichen neuronalen Netzen
Neuronale Netze erzeugen selten direkt eine bestimmte Ausgabe. Stattdessen berechnen sie üblicherweise eine Ausgabe in Format einer Wahrscheinlichkeitsverteilung über alle möglichen Ausgaben. Das liegt daran, weil die von neuronalen Netzen ermittelten Zusammenhänge oft nur Korrelationen sind, deren Aussagekraft variieren kann.
Ein Beispiel: Auf die Frage, ob ein Bild eine Katze oder einen Hund darstellt, erfolgt eine Ausgabe von 80 zu 20. Das heißt, ob auf dem Bild eine Katze ist, muss dann am Ende ein Programmierer entscheiden. Selbst eine hohe Präzision von 99 Prozent kann in bestimmten Anwendungen unzureichend sein. Beispielsweise bei der Diagnose einer Krankheit und der Wahl der richtigen Therapie.
Soll eine generative KI einen Satz schreiben, so entsteht dieser Satz Wort für Wort und zwar jeweils auf Basis einer statistischen Wahrscheinlichkeit in Bezug auf das vorherige Wort und dem jeweiligen Kontext. Die KI hat aber kein Verständnis über den geschriebenen Sachverhalt. Trotzdem funktionieren solche statistischen Verfahren beeindruckend gut.
Weitere verwandte Themen:
- Künstliche Intelligenz (KI) / Artificial Intelligence (AI)
- Was ist ein KI-Modell?
- Künstliche Neuronen
- Machine Learning / Maschinelles Lernen
- KI-Hardware
- KI-Software
- KI-Anwendungen
Lernen mit Elektronik-Kompendium.de
Noch Fragen?
Bewertung und individuelles Feedback erhalten
Aussprache von englischen Fachbegriffen

Computertechnik-Fibel
Computertechnik neu verstehen - jetzt in der 6. Auflage
Die Computertechnik-Fibel ist in einer vollständig überarbeiteten 6. Auflage als Buch, eBook und Bundle erschienen.
Statt einzelne Teile zu lernen, entwickelst du ein Gesamtverständnis moderner Computersysteme. Von der Hardware, Betriebssysteme, Virtualisierung, KI und Quantencomputer.
inkl. MwSt. zzgl. Versandkosten

Computertechnik-Fibel
Alles was du über Computertechnik wissen musst.
Die Computertechnik-Fibel ist ein Buch über die Grundlagen der Computertechnik, Prozessortechnik, Halbleiterspeicher, Schnittstellen, Datenspeicher, Laufwerke und wichtige Hardware-Komponenten.
Artikel-Sammlungen zum Thema Computertechnik
Alles was du über Computertechnik wissen solltest.



